Кодирование текстовой информации в компьютере
Кодирование текстовой информации в компьютере – порой неотъемлемое условие корректной работы устройства или отображения того или иного фрагмента. Как происходит этот процесс в ходе работы компьютера с текстом и визуальной информацией, звуком – все это мы разберем в данной статье.
Вступление

Электронная вычислительная машина (которую мы в повседневной жизни называем компьютером) воспринимает текст весьма специфично. Для нее кодирование текстовой информации очень важно, поскольку она воспринимает каждый текстовый фрагмент в качестве группы обособленных друг от друга символов.
Какие бывают символы?

В роли символов для компьютера выступают не только русские, английские и другие буквы, но и еще знаки препинания, а также другие знаки. Даже пробел, которым мы разделяем слова при печатании на компьютере, устройство воспринимает как символ. Чем-то очень напоминает высшую математику, ведь там, по мнению многих профессоров, ноль имеет двойное значение: он и является числом, и одновременно ничего не обозначает. Даже для философов вопрос пробела в тексте может стать актуальной проблемой. Шутка, конечно, но, как говорится, в каждой шутке есть доля правды.
Какая бывает информация?

Итак, для восприятия информации компьютеру необходимо запустить процессы обработки. А какая вообще бывает информация? Темой этой статьи является кодирование текстовой информации. Мы уделим особенное внимание этой задаче, но разберемся и с другими микротемами.
Информация может быть текстовой, числовой, звуковой, графической. Компьютер должен запустить процессы, обеспечивающие кодирование текстовой информации, чтобы вывести на экран то, что мы, например, печатаем на клавиатуре. Мы будем видеть символы и буквы, это понятно. А что же видит машина? Она воспринимает абсолютно всю информацию – и речь сейчас идет не только о тексте – в качестве определенной последовательности нулей и единиц. Они составляют основу так называемого двоичного кода. Соответственно, процесс, который преобразует поступающую на устройство информацию в понятную ему, имеет название “двоичное кодирование текстовой информации”.
Краткий принцип действия двоичного кода

Почему наибольшее распространение в электронных машинах получило именно кодирование информации двоичным кодом? Текстовой основой, которая кодируется при помощи нулей и единиц, может быть абсолютно любая последовательность символов и знаков. Однако это не единственное преимущество, которое имеет двоичное текстовое кодирование информации. Все дело в том, что принцип, на котором устроен такой способ кодирования, очень прост, но в то же время достаточно функционален. Когда есть электрический импульс, его маркируют (условно, конечно) единицей. Нет импульса – маркируют нулем. То есть текстовое кодирование информации базируется на принципе построения последовательности электрических импульсов. Логическая последовательность, составленная из символов двоичного кода, называется машинным языком. В то же время кодирование и обработка текстовой информации при помощи двоичного кода позволяют осуществлять операции за достаточно краткий промежуток времени.
Биты и байты

Цифра, воспринимаемая машиной, кроет в себе некоторое количество информации. Оно равно одному биту. Это касается каждой единицы и каждого нуля, которые составляют ту или иную последовательность зашифрованной информации.
Соответственно, количество информации в любом случае можно определить, просто зная количество символов в последовательности двоичного кода. Они будут численно равны между собой. 2 цифры в коде несут в себе информацию объемом в 2 бита, 10 цифр – 10 бит и так далее. Принцип определения информационного объема, который кроется в том или ином фрагменте двоичного кода, достаточно прост, как вы видите.
Кодирование текстовой информации в компьютере
Вот сейчас вы читаете статью, которая состоит из последовательности, как мы считаем, букв алфавита русского языка. А компьютер, как говорилось ранее, воспринимает всю информацию (и в данном случае тоже) в качестве последовательности не букв, а нулей и единиц, обозначающих отсутствие и наличие электрического импульса.
Все дело в том, что закодировать один символ, который мы видим на экране, можно при помощи условной единицы измерения, называемой байтом. Как написано выше, у двоичного кода есть так называемая информационная нагрузка. Напомним, что численно она равняется суммарному количеству нулей и единиц в выбранном фрагменте кода. Так вот, 8 бит составляют 1 байт. Комбинации сигналов при этом могут быть самыми разными, как это легко можно заметить, нарисовав на бумаге прямоугольник, состоящий из 8 ячеек равного размера.
Выходит, что закодировать текстовую информацию можно при помощи алфавита, имеющего мощность 256 символов. В чем заключается суть? Смысл кроется в том, что каждый символ будет обладать своим двоичным кодом. Комбинации, “привязываемые” к определенным символам, начинаются от 00000000 и заканчиваются 11111111. Если переходить от двоичной к десятичной системе счисления, то кодировать информацию в такой системе можно от 0 до 255.
Не стоит забывать о том, что сейчас есть различные таблицы, которые используют кодировку букв русского алфавита. Это, например, ISO и КОИ-8, Mac и CP в двух вариациях: 1251 и 866. Легко убедиться в том, что текст, закодированный в одной из таких таблиц, не отобразится корректно в отличной от данной кодировке. Это происходит из-за того, что в разных таблицах к одному и тому же двоичному коду соответствуют различные символы.
Поначалу это было проблемой. Однако в настоящее время в программах уже встроены специальные алгоритмы, которые конвертируют текст, приводя его к корректному виду. 1997 год ознаменовался созданием кодировки под названием Unicode. В ней каждый символ имеет в своем распоряжении сразу 2 байта. Это позволяет закодировать текст, имеющий гораздо большее количество символов. 256 и 65536: есть ведь разница?
Кодирование графики
Кодирование текстовой и графической информации имеет некоторые схожие моменты. Как известно, для вывода графической информации используется периферийное устройство компьютера под названием “монитор”. Графика сейчас (речь идет сейчас именно о компьютерной графике) широко используется в самых разных сферах. Благо, аппаратные возможности персональных компьютеров позволяют решать достаточно сложные графические задачи.
Обрабатывать видеоинформацию стало возможным в последние годы. Но текст при этом значительно “легче” графики, что, в принципе, понятно. Из-за этого конечный размер файлов графики необходимо увеличивать. Преодолеть подобные проблемы можно, зная суть, в которой представляется графическая информация.
Давайте для начала разберемся, на какие группы подразделяется данный вид информации. Во-первых, это растровая. Во-вторых, векторная.
Растровые изображения достаточно схожи с клетчатой бумагой. Каждая клетка на такой бумаге закрашивается тем или иным цветом. Такой принцип чем-то напоминает мозаику. То есть получается, что в растровой графике изображение разбивается на отдельные элементарные части. Их именуют пикселями. В переводе на русский язык пиксели обозначают “точки”. Логично, что пиксели упорядочены относительно строк. Графическая сетка состоит как раз из определенного количества пикселей. Ее также называют растром. Принимая во внимание эти два определения, можно сказать, что растровое изображение является не чем иным, как набором пикселей, которые отображаются на сетке прямоугольного типа.
Растр монитора и размер пикселя влияют на качество изображения. Оно будет тем выше, чем больше растр у монитора. Размеры растра - это разрешение экрана, о котором наверняка слышал каждый пользователь. Одной из наиболее важных характеристик, которые имеют экраны компьютера, является разрешающая способность, а не только разрешение. Оно показывает, сколько пикселей приходится на ту или иную единицу длины. Обычно разрешающая способность монитора измеряется в пикселях на дюйм. Чем больше пикселей будет приходиться на единицу длины, тем выше будет качество, поскольку “зернистость” при этом снижается.
Обработка звукового потока
Кодирование текстовой и звуковой информации, как и другие виды кодирования, имеет некоторые особенности. Речь сейчас пойдет о последнем процессе: кодировании звуковой информации.
Представление звукового потока (как и отдельного звука) может быть произведено при помощи двух способов.
Аналоговая форма представления звуковой информации
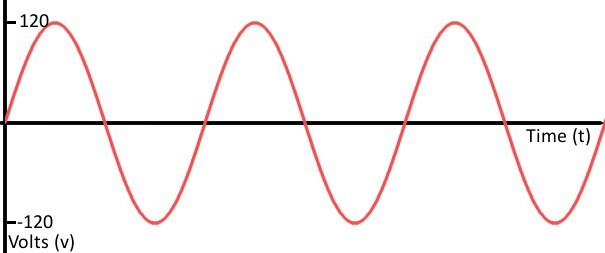
При этом величина может принимать действительно огромное количество различных значений. Причем эти самые значения не остаются постоянными: они очень быстро изменяются, и этот процесс непрерывен.
Дискретная форма представления звуковой информации
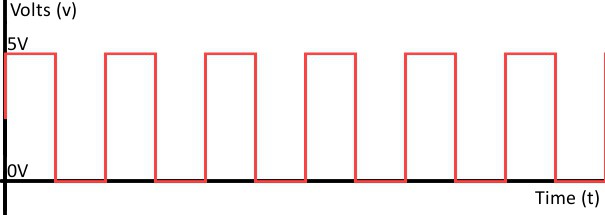
Если же говорить о дискретном способе, то в этом случае величина может принимать только ограниченное количество значений. При этом изменение происходит скачкообразно. Закодировать дискретно можно не только звуковую, но и графическую информацию. Что касается и аналоговой формы, кстати.
Аналоговая звуковая информация хранится на виниловых пластинках, например. А вот компакт-диск уже является дискретным способом представления информации звукового характера.
В самом начале мы говорили о том, что компьютер воспринимает всю информацию на машинном языке. Для этого информация кодируется в форме последовательности электрических импульсов – нулей и единиц. Кодирование звуковой информации не является исключением из этого правила. Чтобы обработать на компьютере звук, его для начала нужно превратить в ту самую последовательность. Только после этого над потоком или единичным звуком могут совершаться операции.
Когда происходит процесс кодирования, поток подвергается временной дискретизации. Звуковая волна непрерывна, она развивается на малые участки времени. Значение амплитуды при этом устанавливается для каждого определенного интервала отдельно.
Заключение
Итак, что же мы выяснили в ходе данной статьи? Во-первых, абсолютно вся информация, которая выводится на монитор компьютера, прежде чем там появиться, подвергается кодированию. Во-вторых, это кодирование заключается в переводе информации на машинный язык. В-третьих, машинный язык представляет собой не что иное, как последовательность электрических импульсов – нулей и единиц. В-четвертых, для кодирования различных символов существуют отдельные таблицы. И, в-пятых, представить графическую и звуковую информацию можно в аналоговом и дискретном виде. Вот, пожалуй, основные моменты, которые мы разобрали. Одной из дисциплин, изучающей данную область, является информатика. Кодирование текстовой информации и его основы объясняются еще в школе, поскольку ничего сложного в этом нет.
Похожие статьи
- Двоичное кодирование информации
- Что такое кодирование и декодирование информации? Алфавит кодирования
- PHP iconv() - преобразование кодировки символов
- Аудио-форматы: виды, предназначение, отличия
- Что такое QR-код, и как им пользоваться?
- Какие правила записи имени файла следует соблюдать: основные требования
- Штрих-коды стран-производителей товаров: полный список, расшифровка, проверка