Свободная таблица символов Юникода
Unicode - это международный стандарт кодировки символов, позволяющий единообразно отображать тексты на любом компьютере в мире, независимо от используемого на нем системного языка.
Основы
Чтобы понять, для чего нужна таблица символов Юникода, давайте сначала разберемся в механизме отображения текста на экране монитора. Компьютер, как мы знаем, обрабатывает всю информацию в цифровом виде, а вывести ее для правильного восприятия человеком должен в графическом. Таким образом, для того чтобы мы могли читать этот текст, надо решить как минимум две задачи:
- Закодировать печатные символы в цифровую форму.
- Обеспечить операционной системе возможность сопоставления цифровой формы с векторными символами, иными словами, найти правильные буквы.
Первые кодировки
Родоначальницей всех кодировок принято считать американскую ASCII. В ней был описан применяемый в английском языке латинский алфавит со знаками препинания и арабские цифры. Именно использованные в ней 128 символов стали основой для последующих разработок - их использует даже современная таблица символов Юникода. Буквы латинского алфавита занимают с тех пор первые позиции в любой кодировке.

Всего ASCII позволяла сохранить 256 символов, но поскольку первые 128 были заняты латиницей, остальные 128 начали использовать во всем мире для создания национальных стандартов. К примеру, в России на ее основе были созданы CP866 и KOI8-R. Назывались такие вариации расширенными версиями ASCII.
Кодовые страницы и «кракозябры»
Дальнейшее развитие технологий и появление графического интерфейса привело к тому, что американским институтом стандартизации была создана кодировка ANSI. Российским пользователям, особенно со стажем, ее версия известна под названием Windows 1251. В ней впервые было применено понятие «кодовая страница». Именно с помощью кодовых страниц, которые содержали символы национальных алфавитов, отличных от латинского, было налажено «взаимопонимание» между компьютерами, используемыми в разных странах.
Вместе с тем наличие большого количества различных кодировок, используемых для одного языка, начало вызывать проблемы. Появились так называемые кракозябры. Возникали они от несовпадения исходной кодовой страницы, в которой создавалась какая-либо информация, и кодовой станицы, применяемой по умолчанию на компьютере конечного пользователя.

В качестве примера можно привести указанные выше кириллические кодировки CP866 и KOI8-R. Буквы в них отличались кодовыми позициями и принципами размещения. В первой они были расставлены в алфавитном порядке, а во второй - в произвольном. Можете представить, что творилось перед глазами пользователя, который пытался открыть такой текст, не имея нужной кодовой страницы или при ее неправильной интерпретации компьютером.
Создание Unicode
Распространение интернета и сопутствующих технологий, таких как электронная почта, привело к тому что в конце концов ситуация с искажением текстов перестала устраивать всех. Передовые компании в области IT образовали Unicode Consortium ("Консорциум Юникод"). Таблица символов, представленная им в 1991 году под названием UTF-32, позволяла хранить более миллиарда уникальных символов. Это был важнейший шаг на пути к расшифровке текстов.

Однако первая универсальная таблица кодов-символов Юникод UTF-32, не получила большого распространения. Основной причиной стала избыточность хранимой информации. Быстро было подсчитано, что для стран, в которых используется латинский алфавит, закодированный с помощью новой универсальной таблицы, текст будет занимать места в четыре раза больше, чем при использовании расширенной таблицы ASCII.
Развитие Unicode
Следующая таблица символов Юникода UTF-16 эту проблему устранила. Кодирование в ней осуществлялось в два раза меньшим количеством бит, но вместе с тем уменьшилось и количество возможных комбинаций. Вместо миллиардов символов она позволяет сохранить только 65 536. Тем не менее она оказалась настолько удачной, что это число, по решению Консорциума, было определено как базовое пространство хранения символов стандарта Unicode.
Несмотря на такой успех, UTF-16 не устраивала всех, поскольку объем хранимой и передаваемой информации по-прежнему завышался в два раза. Универсальным решением стала UTF-8, таблица символов Юникода с переменной длиной записи. Это можно назвать прорывом в данной области.

Таким образом, с введением двух последних стандартов таблица символов Юникода решила проблему единого кодового пространства для всех применяемых в настоящее время шрифтов.
Юникод для русского языка
Благодаря переменной длине кода, применяемого для отображения символов, латиница кодируется в Юникоде так же, как и в своей прародительнице ASCII, то есть одним битом. Для других алфавитов картина может выглядеть по-разному. К примеру, знаки грузинского алфавита используют для кодирования три байта, а знаки кириллического алфавита – два. Все это возможно в рамках использования стандарта UTF-8 Юникод (таблица символов). Русский язык или кириллический алфавит занимает в общем кодовом пространстве 448 позиций, разбитых на пять блоков.
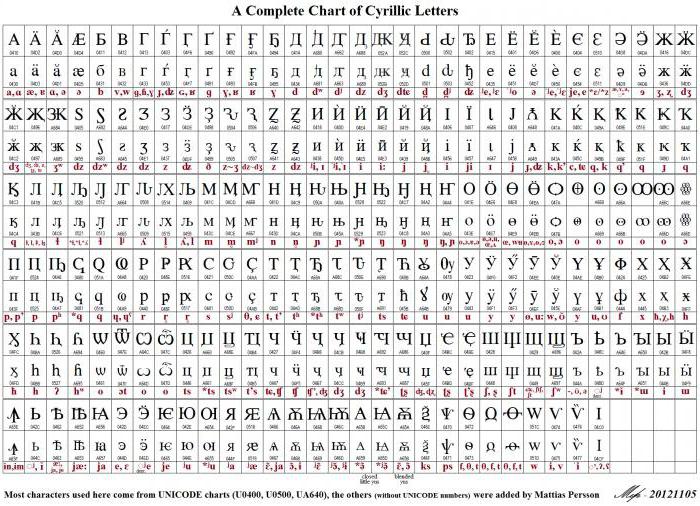
В указанные пять блоков входят основной кириллический и церковнославянский алфавит, а также дополнительные буквы других языков, использующих кириллицу. Ряд позиций выделен для отображения старых форм представления букв кириллицы, а 22 позиции из общего количества пока остаются свободными.
Актуальная версия Юникода
С решением своей первоочередной задачи, которая заключалась в стандартизации шрифтов и создании для них единого кодового пространства, "Консорциум" не прекратил свою работу. Юникод постоянно развивается и пополняется. Последняя актуальная версия этого стандарта 9.0 увидела свет в 2016 году. В нее было включено шесть дополнительных алфавитов и расширен список стандартизованных эмодзи.
Надо сказать, что с целью упрощения исследований, в Юникод добавляются даже так называемые мертвые языки. Такое название они получили потому, что людей, для которых он бы являлся родным, не существует. К этой группе относят также языки, дошедшие до нашего времени только в виде письменных памятников.
В принципе, подать заявку на добавление символов в новую спецификацию Юникода может любой желающий. Правда, для этого придется заполнить приличное количество исходных документов и потратить много времени. Живым примером этому может служить история программиста Теренса Идена. В 2013 году он подал заявку на включение в спецификацию символов, относящихся к обозначению кнопок управления питанием компьютера. В технической документации они использовались с середины 70-х годов прошлого века, но до появления спецификации 9.0 не входили в состав Unicode.
Таблица символов
На каждом компьютере, независимо от применяемой операционной системы, используется Юникод-таблица символов. Как пользоваться этими таблицами, где их найти и для чего они могут пригодиться обычному пользователю?
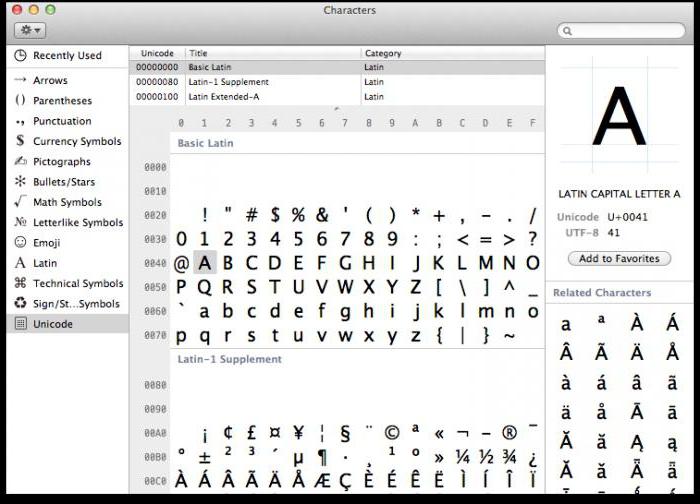
В ОС Windows таблица символов располагается в разделе меню «Служебные». В семействе операционных систем Linux ее обычно можно найти в подразделе «Стандартные», а в MacOS – в настройках клавиатуры. Основное назначение этой таблицы – ввод в текстовые документы символов, которые не расположены на клавиатуре.
Применение для таких таблиц можно найти самое широкое: от ввода технических символов и значков национальных денежных систем до написания инструкции по практическому применению карт Таро.
В заключение
Юникод используется повсеместно и вошел в нашу жизнь вместе с развитием интернета и мобильных технологий. Благодаря его использованию существенно упростилась система межнациональных коммуникаций. Можно сказать, что внедрение Юникода является показательным, но совершенно незаметным со стороны примером использования технологий для общего блага всего человечества.
Похожие статьи
- Символы "альфа", "бета", "гамма" и "омега" на компьютере: способы вставки в текст
- Как найти знак корня на клавиатуре?
- Как ставить знаки на клавиатуре: советы и рекомендации
- Как поставить кавычки-"елочки"? Советы и рекомендации
- Символ "галочка": учимся печатать в Word
- Как определить кодировку? Зачем это нужно?
- Учимся ставить верхнюю запятую в тексте